快速入门kafka③ kafka优点及技术架构
本文共 1039 字,大约阅读时间需要 3 分钟。
Kafka优点
可靠性强:分布式的,分区,复制和容错
可扩展性:无需停机进行扩展。 耐用性:消息会尽可能快速的保存在磁盘上,持久化。 性能高:对于发布和定于消息都具有高吞吐量,保证零停机和零数据丢失Kafka应用场景
指标分析:用于操作监控数据,分析各种指标。
日志收集:收集各个业务的数据发送到kafka TOPIC里 流式处理:数据实时打入kafka,实时计算框架(sparkstreaming flink)实时在kafka中消费数据Kafka技术架构(宏观)
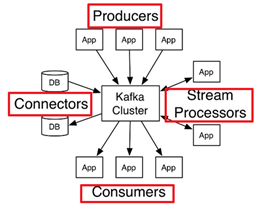
Producer: 应用程序发布记录流至一个或者多个kafka的主题(topics)
Consumer: 应用程序订阅一个或者多个主题(topics)Connectors: 允许构建和运行可重用的生产者或者消费者StreamProcessors: 允许应用程序充当流处理器Kafka架构内部细节剖析(维观)

生产者(Producer):kafka当中的消息生产者,生产者通过topic进行归类保存到kafka的broker里面去
主题(topic):一个主题可以有零个,一个或者多个消费者定阅写入的数据。可以有无数个主题
分区(partition): 每一个分区的数据是有序的,多个partition之间是无序的。Partition数量决定了每个Consumer Group中并发消费者的最大数量。
分区和消费组之间的关系:
同一个组中的消费者对于同一条信息只能消费一次
消费者应该小于等于该主题下的分区数, Partition=消费任务并发度=刚刚好,每个任务取一个partition数据 partition>消费任务并发度=有部分消费任务读取多个分区的数据 partition<消费任务并发度=有部分任务空闲任何时候,分区中的一条数据只能被一个消费组中的一个消费任务读取。 总结:分区数越多,用一时间可以有越多的消费者来进行消费,消费数据的速度就会越快,提高消费的性能lsr表示:当前可用的副本列表
Segment: 一个partition当中有多个segment,一个segment有一个.log文件和一个.index文件组成
index file: 采取稀疏索引存储方式。(只是存储一部分索引,不存储所有数据的索引) 稀疏能够节省存储空间,偏移量(offset):每条消息在文件中的位置称为offset(偏移量)
消费者(Consumer):任何时候一个消费都必定需要属于某一个消费组当中。
转载地址:http://nakzi.baihongyu.com/
你可能感兴趣的文章
将整数转换为宽字符串
查看>>
在类中定义enum实现整数常量功能
查看>>
suse11通过安装最新内核可以上网的经验
查看>>
SUSE静态配置IP成功上网
查看>>
通过sleep让程序等待外部条件改变
查看>>
通过等待键盘输入让程序等待外部条件改变
查看>>
通过限制循环次数来避免死循环
查看>>
ADO连接字符串
查看>>
字符数组的位置决定程序能否成功执行--不明白
查看>>
拷贝代码时没有仔细检查,导致误修改了函数参数
查看>>
MySQL批量导入数据SQL语句(CSV数据文件格式)
查看>>
ADO连接Oracle
查看>>
遍历Windows系统中所有进程的名字(*.exe)
查看>>
进程看门狗
查看>>
线程看门狗
查看>>
调试代码的宏定义
查看>>
创建、重命名文件
查看>>
文件大小保护
查看>>
删除指定目录下所有文件及目录
查看>>
XDR-从文件空间解码整数
查看>>